Build an API to Fetch Most Popular Languages
Viewing typescript
switch to python
With the TopLanguages Materialzied View created in the previous step, you can build a Consumption API to fetch data from this view and make it available for your other applications.
A Consumption API enables you to create specific API endpoints that allow your applications to access and retrieve data. It serves as the final customization layer, where you can use query parameters to dynamically generate and execute SQL queries.
In this module, you will implement a Consumption API that will:
- Dynamically generate and execute a query to extract analyzed data from the
TopLanguagesmaterialized view - Return a ranked list of programming languages based on either:
- The number of repositories using the language
- The total number of kilobytes of code written in the language
- The average number of kilobytes of code written per repository using the language
The ranking criteria will depend on the Query Parameters specified in the request URL.
Generate a New File & Route for your API
Leverage the Moose CLI to Initialize a New Consumption API
npx moose-cli consumption init rankedLanguagesmoose-cli consumption init ranked_languagesThis command will generate a new file named rankedLanguages.tsranked_languages.py inside the /apis folder of your project:
- rankedLanguages.ts
- ranked_languages.py
It will also create a corresponding API endpoint at: https://[YOUR_FORWARDING_URL]/consumption/rankedLanguageshttps://[YOUR_FORWARDING_URL]/consumption/ranked_languages. Making an HTTP GET request to this URL will execute the route handler function defined inside the file.
Moose uses file-based routing conventions to map the files in the apis
folder to corresponding API endpoints. This means that the file
rankedLanguages.tsranked_languages.py will automatically map to the
/consumption/rankedLanguages/consumption/ranked_languages endpoint.
Open and Inspect the File
Go to the /apis folder and open rankedLanguages.tsranked_languages.py. You should see the following code:
import { ConsumptionUtil } from "@514labs-moose-lib";
// This file is where you can define your API templates for consuming your data
// All query_params are passed in as strings, and are used within the sql tag to parameterize your queries
interface QueryParams {}
export default async function handle(
{}: QueryParams,
{ client, sql }: ConsumptionUtil,
) {
return client.query.execute(sql``);
}from moose_lib import MooseClient
from typing import Optional
def run(client: MooseClient, params, jwt: Optional[dict] = None):
return client.query.execute("", {})
- Importing
ConsumptionUtilMooseClient: This utility type from the Moose library gives you access to the database client (client) and SQL query tagged template literals (sql)
- Default Export: The default export is an asynchronous function named
handle, which takes two parameters:- An object conforming to an empty
QueryParamsinterface. You will define this interface in the next step to represent the different parameters to use in your dynamic query. - The
ConsumptionUtilobject you imported
- An object conforming to an empty
runFunction: Therunfunction is the entry point for the Consumption API. It takes three parameters:- An instantiated
MooseClient - A
paramsdictionary containing the query parameters. Query parameter names are keys in the dictionary, and the values are the query parameter values. - An optional
jwtdictionary containing the JWT payload from the authenticated user. We will not use this in this tutorial, but it is useful for implementing authorization in your Consumption API.
- An instantiated
Define the QueryParams Interface
This interface should contain one key: rankBy. This key should be a string and have a value of either total_projects, total_repo_size_kb, or average_repo_size_kb. The specified value will determine the ranking criteria for the results.
You can use a Union type to specify the possible values for the rankBy parameter. Moose will automatically infer the type validation and parsing for the rankBy parameter based on the value you provide.
import { createConsumptionApi, ConsumptionHelpers as CH } from "@514labs/moose-lib";
import { tags } from "typia";
interface QueryParams {
rankBy: "total_projects" | "total_repo_size_kb" | "average_repo_size_kb";
limit: number & tags.Minimum<1> & tags.Type<"int32">;
}These parameters are set in the request URL as key-value pairs, and their values will be injected into the query that you will execute against the database.
Implement the handle() Function
import { createConsumptionApi, ConsumptionUtil, ConsumptionHelpers as CH } from "@514labs/moose-lib";
export interface QueryParams {
rankBy: "total_projects" | "total_repo_size_kb" | "average_repo_size_kb";
}
export default createConsumptionApi<QueryParams>(
{ rankBy = "total_projects" }: QueryParams,
{ client, sql }: ConsumptionUtil
) {
return client.query.execute(
sql`SELECT
language,
countMerge(total_projects) AS total_projects,
sumMerge(total_repo_size_kb) AS total_repo_size_kb,
avgMerge(average_repo_size_kb) AS average_repo_size_kb
FROM TopLanguages
GROUP BY language
ORDER BY ${CH.column(rankBy)} DESC`
);
}from moose_lib import MooseClient
from dataclasses import dataclass
# Define the expected query parameters for this API endpoint
# rank_by: Determines how to sort the results, defaults to sorting by total number of projects
@dataclass
class QueryParams:
rank_by: str = "total_projects"
def run(client: MooseClient, params: QueryParams):
# Extract the rank_by parameter from the request
rank_by = params.rank_by
# Validate that rank_by is one of the allowed values
# Can sort by:
# - total_projects: Number of repos using each language
# - total_repo_size_kb: Total KB of code in each language
# - avg_repo_size_kb: Average KB per repo for each language
if rank_by not in ["total_projects", "total_repo_size_kb", "avg_repo_size_kb"]:
raise ValueError("Invalid rank_by value. Must be one of: total_projects, total_repo_size_kb, avg_repo_size_kb")
# Build and execute query to get ranked programming languages
# Uses aggregate functions to:
# - countMerge: Get final count of projects per language
# - sumMerge: Get total KB of code per language
# - avgMerge: Get average KB per repo per language
query = f'''
SELECT
language,
countMerge(total_projects) AS total_projects,
sumMerge(total_repo_size_kb) AS total_repo_size_kb,
avgMerge(avg_repo_size_kb) AS avg_repo_size_kb
FROM
TopLanguages
GROUP BY
language
ORDER BY
{rank_by} DESC
'''
# Execute the query, passing rank_by as a parameter for safety
return client.query.execute(query, { "rank_by": rank_by })
The function returns ranked programming languages based on the rankByrank_by parameter, defaulting to total_projects if not specified. Invalid parameter values will throw an error.
- Use the parameter
?rankBy=total_repo_size_kbto rank results by the total number of bytes written in each language across all the people who starred your repo.
Test Out the API Endpoint
Call the API From Your Terminal via curl
curl -X GET https://[YOUR_FORWARDING_URL]/consumption/rankedLanguagescurl -X GET https://[YOUR_FORWARDING_URL]/consumption/ranked_languagesRemember when you saved it earlier?
Test the Consumption API Endpoint Query Parameters via curl
curl -X GET https://[YOUR_FORWARDING_URL]/consumption/rankedLanguages\?rankBy\=total_repo_size_kbcurl -X GET https://[YOUR_FORWARDING_URL]/consumption/ranked_languages\?rank_by\=total_repo_size_kb(Optional) For a Better Experience, Use Your API Client of choice
If you agreed to install the Recommended Extensions upon initially opening your Moose project in VSCode, you will have the Thunder Client extension autmatically installed in your project workspace. You can locate the extension via the lightning bolt icon.
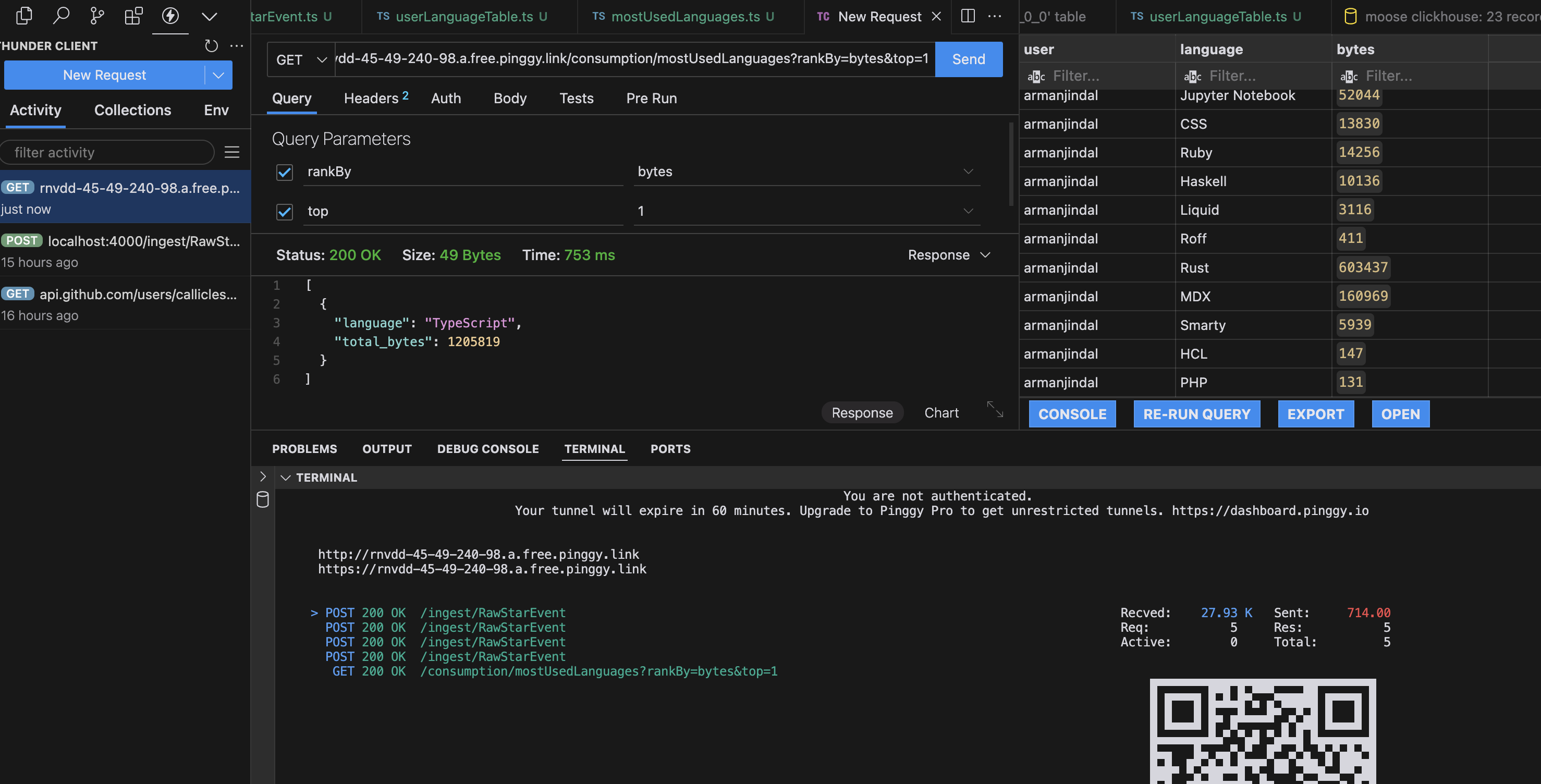
Try changing the query parameters to see the results change. The query parameters do not need to be backslashed in the URL, for example:_
https://[YOUR_FORWARDING_URL]/consumption/rankedLanguages?rankBy=total_repo_size_kbhttps://[YOUR_FORWARDING_URL]/consumption/ranked_languages?rank_by=total_repo_size_kbYou’ve just built an impressive real-time analytics service for GitHub star events using Moose! Let’s recap your amazing journey:
- You created a Data Model and set up a GitHub webhook to ingest star events in real-time.
- You created a Streaming Function to process and enrich the raw star event data.
- You implemented a Block to analyze user programming languages.
- You built a Consumption API to fetch insights about the most used languages.